
Image Inpainting with Partial Convolutions: Making Holes Disappear
By Keng‑Lien Lin & Henry Lin
🌟 Project Overview
In our ECE 176 final project, we implemented a deep learning–based image inpainting model inspired by Liu et al. (2018). This model tackles the challenge of reconstructing missing parts of an image—especially when the holes are irregularly shaped.
We trained our model on human face images from the Flickr‑Faces‑HQ (FFHQ) dataset, using partial convolution layers within a modified U‑Net architecture. These layers skip over missing regions during convolution, enabling more realistic and seamless image completion.
Goal: Fill in irregular holes in face images using a network that learns both global semantics and local details.
🔍 Motivation
Traditional patch‑based inpainting works for small, patterned holes—but struggles with larger or irregularly shaped missing regions. Recent deep learning models often handle only rectangular masks, leading to visible artifacts around non‑rectangular holes.
Partial convolutions are masking‑aware operations that only consider valid (non‑hole) pixels during convolution and normalize outputs accordingly, reducing shape‑dependent artifacts.
📚 Related Work
- Patch‑based inpainting (Telea, 2004): Effective for textures, but limited on complex scenes.
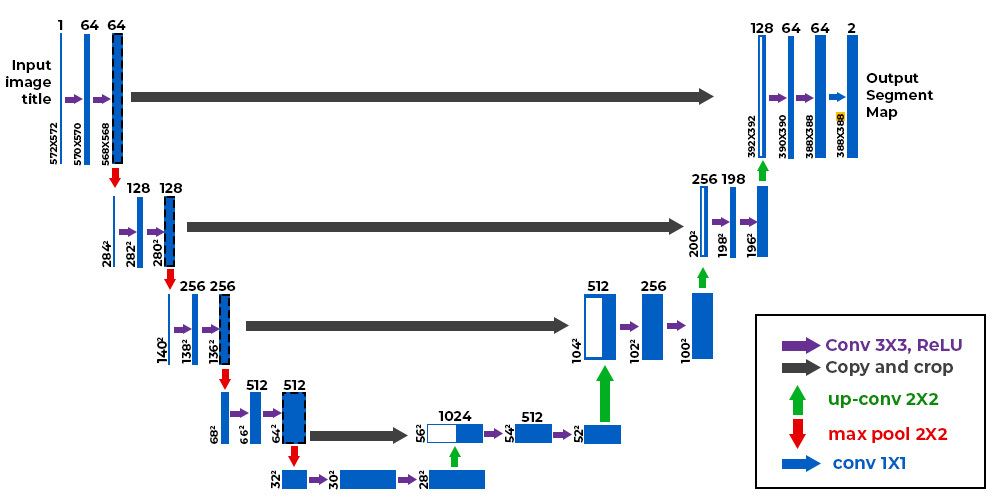
- U‑Net architecture (Ronneberger et al., 2015): Encoder–decoder with skip connections for detail preservation.
- Contextual attention + gated convolutions (Yu et al., 2018): Improved refinement at the cost of higher memory usage.
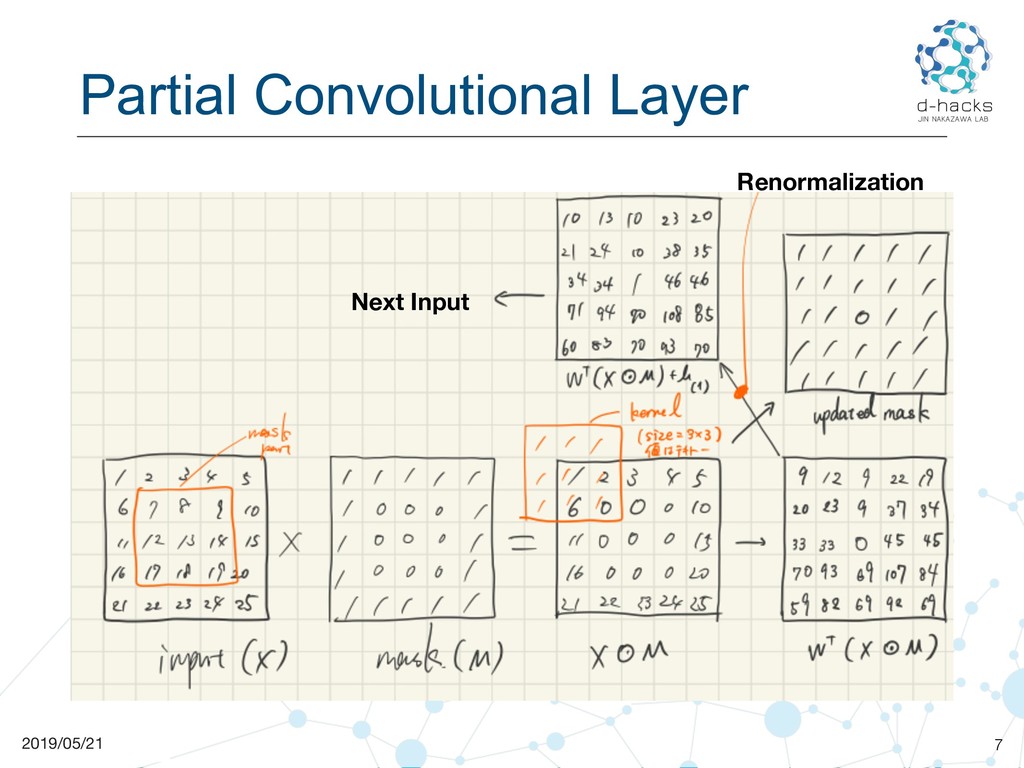
🧠 Partial Convolution Primer
A partial convolution at each location only processes pixels marked valid by a binary mask (M):
\[x' = \begin{cases} \dfrac{W^T (X \odot M)}{\sum(M)} + b, & \text{if }\sum(M) > 0,\\[1ex] 0, & \text{otherwise}, \end{cases}\]- (X): input patch
- (M): binary mask (1 = known, 0 = hole)
- (W): convolution kernel
- (b): bias term
After each layer, the mask is updated so that any location with (\ge1) valid pixel becomes valid in deeper layers.
🏗️ Network Architecture
We adapted a U‑Net model with:
- Partial convolution layers replacing standard convolutions
- Encoder: ReLU + BatchNorm
- Decoder: LeakyReLU ((\alpha = 0.2)) + BatchNorm
- Nearest‑neighbor upsampling
- One fewer down‑/up‑sampling stage (to suit 256×256 images)

⚖️ Loss Function
A multi‑term loss ensures both pixel accuracy and perceptual quality:
- $(L_{\text{valid}})$: per‑pixel loss on known regions
- $(L_{\text{hole}})$: per‑pixel loss on inpainted regions
- $(L_{\text{perceptual}})$: feature‑space difference via VGG‑16
- $(L_{\text{style_out}}) \& (L_{\text{style_comp}})$: style consistency via Gram matrices
- $(L_{\text{tv}})$**$: total variation loss for smoothness
🏃 Training Setup
- Dataset: FFHQ (52 k face images at 256×256)
- Masks: 1 000 free‑form binary masks
- Hardware: Nvidia RTX 2060
- Batch Size: 12
- Optimizer: Adam (LR = 0.0002)
- Training Time: ~2 days → 35 epochs (≈10% of original training)
📊 Experiments & Results
Case 1: Sparse Free‑form Masks
Model blends the hole with surroundings and recovers details (e.g., glasses, facial features).
Artifacts (rainbow specks, color blobs) appear in dense regions but decrease with more training.
Case 2: Large Central Masks
Even with minimal input, the model learns face structure and symmetry (e.g., beard extension).
Borders are more pronounced; color matching is less accurate.
Case 3: Comparison with Fully Trained Models
Compared to Liu et al.’s PartialConv and GntIpt models, our partially trained network shows more artifacts and color mismatches.
🧩 Key Insights
- Partial convolutions effectively reduce mask‑shape artifacts.
- Even limited training yields semantic understanding of faces.
- Longer training and fine‑tuning should significantly improve output quality.
💡 Conclusion
Our implementation of masking‑aware partial convolutions demonstrates robust free‑form image inpainting capabilities. With additional training and hyperparameter tuning, this approach promises strong performance for real‑world image editing and restoration tasks.
📸 Acknowledgments
- Dataset: Flickr‑Faces‑HQ (Karras et al., 2019)
- Core Paper: Liu et al., 2018, “Image Inpainting for Irregular Holes using Partial Convolutions”
- U‑Net Reference: Ronneberger et al., 2015